【2025年最新】ロジスティック回帰分析とは?マーケティングに活かす予測モデル入門

 ポスト
ポスト シェア
シェアデータに基づく意思決定が求められる現代において、「ロジスティック回帰分析」はマーケティングやビジネス分析の場面で頻繁に使われる統計手法です。購買予測や離脱防止、不正検知など、実務に直結する用途が多く、分析初心者でも基本を理解すれば実装可能です。本記事では、ロジスティック回帰分析の定義からユースケース、導入手順、注意点、Pythonを使った実装例まで体系的に解説します。

目次
ロジスティック回帰分析の定義と基本概念
ロジスティック回帰分析とは、結果が2つに分類される事象(例:購入する・しない)に対して、どのような要因が関与しているかを数値的に評価し、その発生確率を予測する分析手法です。通常の回帰分析とは異なり、目的変数が連続値ではなく「0か1」で表される点が特徴です。
たとえば、広告を見たユーザーが商品を購入するかどうか、あるいはサービスを継続するかどうかを予測することができます。確率をもとにした意思決定が可能になるため、マーケティング戦略の最適化に活用されています。
ロジスティック回帰分析が使われる場面
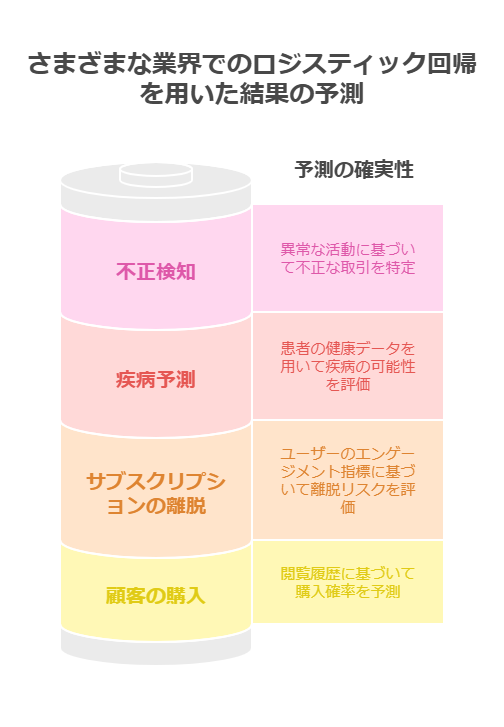
ロジスティック回帰分析は、「はい/いいえ」などの2択の結果を予測するのに適しており、さまざまなビジネス分野で活用されています。以下に、代表的なユースケースを詳しく紹介します。
顧客の購買予測(ECサイトなど)
オンラインショッピングサイトでは、ユーザーが商品を購入するかどうかを予測するためにロジスティック回帰分析が活用されています。たとえば、あるユーザーが過去にどんな商品を見て、どれをカートに入れたかといった履歴をもとに、「この商品を買う確率は80%」といった数値を算出します。
このように予測された結果をもとに、購入の可能性が高いユーザーにだけ割引クーポンを配布することで、コストをかけすぎずに売上を効率よく伸ばすことができます。これは「ターゲティング広告」の最適化にも直結します。
サブスクリプションサービスの離脱予測
動画配信サービスや音楽アプリなどの定額制サービスでは、「そろそろ解約しそうなユーザー」を見つけることが非常に重要です。ここでもロジスティック回帰分析が使われます。
たとえば、ログイン頻度が減っていたり、お気に入りリストに新しい項目が追加されていなかったりするユーザーは、離脱のリスクが高いと判断されます。こうした予測にもとづいて、割引キャンペーンやリマインド通知を送ることで、離脱を未然に防ぐ施策が打てます。
医療分野でのリスク評価(疾病予測)
医療分野では、患者の健康データをもとに、病気にかかるリスクを予測するためにロジスティック回帰分析が活用されています。たとえば、年齢、喫煙歴、血圧、体重といったデータを用いて、「心臓病になる可能性は60%」といったリスク評価を行うことができます。
この分析結果に基づいて、リスクの高い患者には定期的な健康診断を勧めたり、生活習慣の改善指導を行うなど、予防医療への対応が可能になります。
金融業界での不正検知
銀行やクレジットカード会社では、不正利用や詐欺行為をいち早く発見するために、ロジスティック回帰分析が使われています。たとえば、通常の購買パターンと大きく異なる取引(深夜に高額な買い物をするなど)を見つけた際に、それが不正である確率を分析します。
「この取引は不正である確率が90%」と判断された場合、自動的にカードの一時停止処理やアラート通知が行われる仕組みに活かされています。人の目では見逃すような異常も、データに基づいて瞬時に検出できます。
ロジスティック回帰分析の仕組みと実行手順
ロジスティック回帰分析は、「ある出来事が起こるかどうか(例:購入する/しない)」を予測するための統計モデルです。数学的には「シグモイド関数(S字カーブ)」を使って、0〜1の確率を出力し、一定の閾値(たとえば0.5)を超えたら「起こる」と判断します。
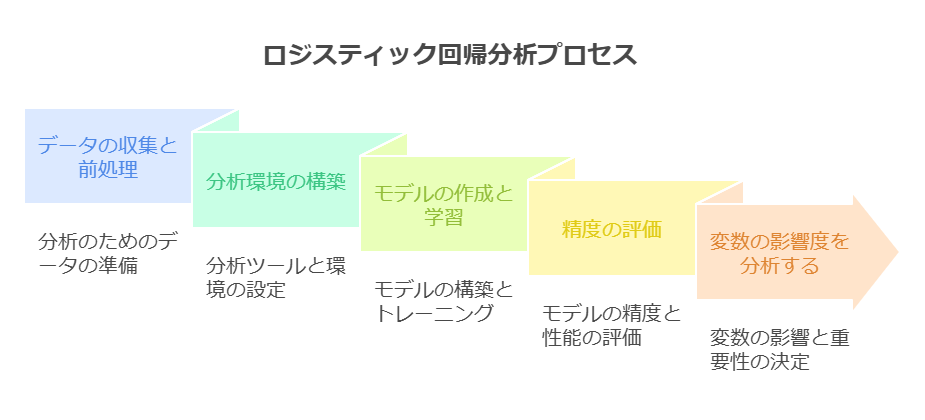
この仕組みを活用し、実際に分析を進めるには、以下の5つのステップを踏むことが一般的です。
STEP 1:データの収集と前処理
まずは、分析に使用するデータを準備します。対象となるデータは、顧客の属性(年齢、性別、購入履歴など)や行動履歴などです。
この段階で行う処理は以下のとおりです。
- 欠損値(空欄データ)の処理:平均値で補完したり、除外したりします
- 外れ値の確認:極端な値が予測モデルをゆがめることがあるため、チェックが必要です
- 標準化:値のスケール(大きさ)を揃えて学習効率を高めます
- カテゴリ変数のエンコーディング:文字データ(例:性別「男性」「女性」など)を数値に変換します
この「前処理」が不十分だと、どんなに高度なモデルを使っても正確な結果は得られません。
STEP 2:分析環境の構築
データの準備が整ったら、分析を行う環境を整えます。実務では主に以下のプログラミング言語やツールが使われます。
- Python:機械学習ライブラリ「scikit-learn」が標準的
- R:統計解析に強く、視覚化も容易
- Excel+アドイン:簡易的な分析であれば使用可能
とくにPythonでは、LogisticRegressionクラスを用いることで、数行のコードでモデル構築が可能です。
STEP 3:モデルの作成と学習
次に、用意したデータをもとにロジスティック回帰モデルを作成し、学習(トレーニング)させます。
- まず、データを訓練データとテストデータに分割します(一般的には8:2や7:3の比率)
- 訓練データを使ってモデルにパターンを学ばせ、テストデータで性能を検証します
Pythonの場合、以下のようなコードで実行します
pythonコピーする編集するfrom sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
モデルは、入力された説明変数(例:年齢、来店回数など)と目的変数(例:購入する・しない)の関係を学習し、今後の予測に活かします。
STEP 4:精度の評価
モデルがどれだけ正確に予測できるかを判断するためには、「評価指標」を使います。代表的な指標は以下の通りです。
- 正解率(Accuracy):予測が正解した割合
- 再現率(Recall):本来「起きる」べき事象をどれだけ見逃さずに予測できたか
- 精度(Precision):予測で「起きる」と判断した中で、実際に起きたものの割合
- 混同行列(Confusion Matrix):予測結果と実際の結果の対応表
ビジネス上は「正解率だけ高い」よりも、「どのタイプの間違いが起きているか」を理解することが重要です。たとえば、離脱を防ぎたいユーザーを見逃すと損失につながるため、再現率が重視されることもあります。
STEP 5:変数の影響度を分析する
最後に、どの変数(要因)が結果にどれだけ影響しているかを確認します。これによって、戦略的な意思決定に役立つヒントを得ることができます。
- 係数(回帰係数):各説明変数が結果に与える方向性(プラスかマイナスか)と大きさ
- オッズ比(odds ratio):変数が1単位増えたときに、発生確率がどれくらい変化するか
たとえば、「来店頻度が1回増えると、購入オッズが1.8倍になる」といったように、数字で示されると非常に実務的な示唆につながります。
ロジスティック回帰分析のメリット
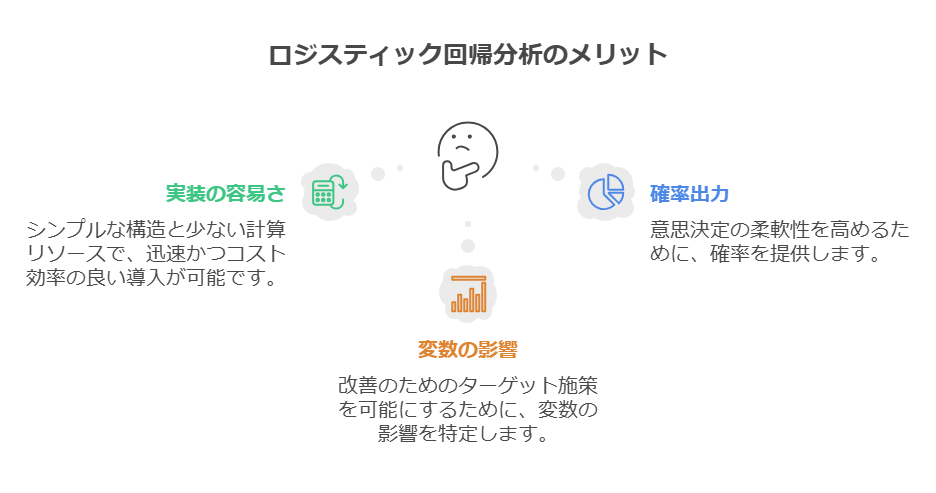
ロジスティック回帰分析は、シンプルながら応用範囲が広く、ビジネスやデータサイエンスの現場で重宝される手法です。以下に代表的なメリットを紹介します。
実装が比較的容易で、導入しやすい
他の機械学習モデル(ランダムフォレストやニューラルネットワークなど)と比べて、ロジスティック回帰は構造がシンプルです。PythonやRなどのツールを使えば、数行のコードでモデルの構築と実行が可能なため、初学者にも扱いやすい分析手法です。
また、計算リソースの消費も少なく、小規模なデータセットでも十分に効果を発揮するため、導入コストを抑えた分析が実現できます。
出力が確率であるため、意思決定に直結する
ロジスティック回帰分析は、「はい/いいえ」といった2値の分類だけでなく、「ある出来事が起こる確率」を0〜1の数値で出力します。これにより、意思決定の柔軟性が高まります。
たとえば、あるユーザーが商品を購入する確率が「72%」と出た場合、それをもとに「クーポンを送るべきか」「再ターゲティング広告を配信するべきか」といった判断を下すことができます。単なる分類よりも現実的な施策につながりやすいのが強みです。
変数ごとの影響度がわかるため、改善施策につなげやすい
ロジスティック回帰分析では、各説明変数(年齢、性別、購入回数など)が目的変数(購入する・しない)にどの程度影響しているかが「係数」や「オッズ比」として出力されます。
これにより、「どの要因が最も強く影響しているのか」が定量的にわかります。たとえば、「過去30日間の訪問回数」が高いオッズ比を持っていれば、それを増やすための施策(メール配信、SNSキャンペーンなど)を強化することができます。
ロジスティック回帰分析の注意点

便利なロジスティック回帰分析ですが、使用にあたっては注意すべき点も多く存在します。これらを軽視すると、誤った判断や分析ミスを招く可能性があります。
サンプル数が少ないとモデルが不安定になる
ロジスティック回帰分析では、一定以上のデータ件数がないと、結果がブレやすくなります。特に、「発生しない」ケースばかりで「発生する」ケースが極端に少ないようなデータ構造では、モデルの学習が偏りやすくなります。
たとえば、100人中わずか5人しか購買していないデータに対してモデルを構築すると、結果の信頼性が低下するため、十分なサンプル数の確保が必要です。
説明変数に強い相関があるとモデルが不安定になる(多重共線性)
説明変数同士が強い相関を持っていると、どの変数が実際に結果に影響しているのかが不明瞭になります。これを多重共線性と呼び、モデルの解釈性と予測精度を下げる要因となります。
たとえば、「年齢」と「生まれ年」を同時にモデルに入れると、ほぼ同じ情報を2重に扱うことになり、係数の値が不安定になる可能性があります。相関が高い変数は除外するか、主成分分析などで次元圧縮を行うのが一般的な対処法です。
データの前提条件を無視すると誤解を招く
ロジスティック回帰では、いくつかの前提が暗黙的に存在します。たとえば、「説明変数と目的変数が線形に関連している」「観測値が独立である」などの前提が成り立っていない場合、モデルの出力が不正確になります。
特に、同じユーザーから複数回データが取られているような場合(例:同一顧客の過去10件の購入履歴など)は、「独立性」の仮定が崩れてしまい、誤った分析につながります。
Pythonによるロジスティック回帰の実装例
以下はPythonで簡易的にロジスティック回帰分析を行うサンプルコードです。
pythonコピーする編集するimport pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# データの読み込み
data = pd.read_csv('data.csv')
# 特徴量と目的変数を定義
X = data[['feature1', 'feature2']]
y = data['target']
# データ分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデル構築と学習
model = LogisticRegression()
model.fit(X_train, y_train)
# 予測と精度評価
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
ロジスティック回帰分析におけるよくある質問(Q&A)
多項分類(3値以上)には使えない?
3つ以上の結果を予測したい場合には、「多項ロジスティック回帰(Multinomial Logistic Regression)」という拡張版を使います。
たとえば、ユーザーが「商品A・商品B・商品Cのどれを選ぶか」というように3択以上の選択肢がある場合でも、ロジスティック回帰を応用することで、それぞれの選ばれる確率を出すことが可能です。
線形回帰との違いは?
線形回帰は、「ある数値をどれくらいになるか」を予測する手法です(例:売上金額やテストの点数を予測)。一方で、ロジスティック回帰は「ある事象が起きるかどうか(0か1)」を予測する手法です。
もう少しわかりやすく言えば、
- 線形回帰 → 数値そのものを当てる(何点になる?いくら売れる?)
- ロジスティック回帰 → 起きるかどうかを当てる(買う?買わない?)
というように、予測する対象の性質が根本的に違います。
まとめ
ロジスティック回帰分析は、確率という形で未来の行動を予測し、戦略に落とし込むための重要な手法です。マーケティング、医療、金融などあらゆる分野で活用されており、初心者でも手順を踏めば実装が可能です。予測精度を高めるためには、前提となるデータの整備と、モデルの評価・改善が不可欠です。理論だけでなく、実データを用いて試行錯誤することが、実務での活用につながります。
この記事を読んだ方におすすめの記事はこちら
- プロフィール
-
- マーケティング支援会社での10年以上の経験。 各種マーケティングに精通し、累計運用額50億円以上・30媒体以上の実績を誇る。








