【2025年最新】クローラーを上手に管理!クローラー制御とSEOに役立つ設定方法

 ポスト
ポスト シェア
シェア検索結果で上位に表示されるサイトはどのように決まっているのか、気になりませんか?
そこで鍵を握るのがクローラーの存在です。クローラーとは、検索エンジンがインターネット上のWebページを発見し、その情報を収集するために使うプログラムのことです。この仕組みのおかげで、ユーザーは検索エンジンを使って必要な情報を簡単に見つけることができるのです。ここでは、クローラーの基本やSEOへの影響、効率よくクロールさせる方法について解説します。

目次
クローラーとは?その基本と役割を理解しよう
クローラーとは、インターネット上のページを自動で巡回し、情報を収集する“ロボット”のような存在です。
Google・Bing・Yahoo!などの検索エンジンには、それぞれ独自のクローラーがあり、常に膨大なWebページを訪問して内容をデータベースに保存しています。
収集された情報は「インデックス」と呼ばれるデータベースに登録され、ユーザーが検索するときに参照されます。検索エンジンはこのデータをもとに、ユーザーの検索意図に合った結果を表示しているのです。
例えば、Googleのクローラーは「Googlebot」と呼ばれ、毎日膨大な数のページを巡回しています。
2025年最新・クローラー動向まとめ(AIボット増加/クロール量の変化)
GPTBot・Applebot等のAI系クローラー記載がrobots.txtで急増
ここ1~2年で大きな変化は、AI関連クローラーの存在感が急拡大している点です。GPTBot(OpenAI)、Applebot(Appleの検索技術)、ClaudeBot(Anthropic)などが次々に登場し、robots.txtへの明記率も急増しました。調査によると、主要サイトの2割以上がGPTBotを明記し、アクセスを「許可するか拒否するか」をポリシーとして示しています。
こうした流れは、AI学習にデータを提供するかどうかをサイト運営者が意思表示する時代になったことを意味します。ただしrobots.txtはあくまでガイドラインであり、すべてのクローラーが従うとは限らない点には注意が必要です。信頼性のある検索エンジン系クローラーは遵守しますが、無名のAIボットや悪質なスクレイピングは無視する可能性があります。
検索系クローラーのトラフィック傾向(2024→2025の伸び)
AIクローラーの存在感が注目されていますが、従来の検索系クローラーも依然として活発です。Cloudflareの分析では、2024年から2025年にかけてクロール全体のトラフィックが約18%増加しました。特にGooglebotは前年より大きく伸びており、検索サービス側がウェブ全体の情報をこれまで以上に精緻に収集していることが分かります。
巡回量の増加は、サーバー負荷やクロールバジェット(巡回できる上限量)にも直結します。そのため、不要なページをクロールさせない工夫や、重要ページの読み込み速度改善が今まで以上に重要です。今後は検索エンジン自体がAIを組み込み、単なる収集から「意味理解型クロール」へと進化していくと予測されます。
クローラーの仕組み 検索エンジンでの働き
クローラーがWebページを発見する流れ
クローラーがWebページを発見するには、「リンク」をたどる仕組みが使われています。例えば、あるページに別のページへのリンクが貼られていると、そのリンクを辿って次のページにアクセスする仕組みです。こうしてリンクを次々に追いかけながら、Web全体を巡回しています。そのため、クローラーが巡回しやすいようにサイトマップを用意することが効果的です。
クローリングとインデックスの違いとは?
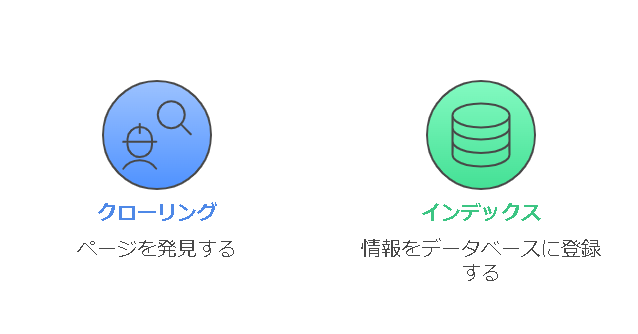
クローリングとは、クローラーがページを「見に行く」ことを指します。
一方、インデックスとは、収集した情報を検索エンジンのデータベースに「登録する」ことです。つまり、クローリングとインデックスは検索結果に表示するための二段階のプロセスといえます。つまり、クローリングが成功してもインデックスされなければ、検索結果には表示されません。
クローラーがSEOに与える影響とは?検索順位に関わる理由を解説
クローラーがサイトに訪れる理由と重要性
クローラーが頻繁にサイトを訪れると、そのサイトは検索エンジンによって重要だと見なされやすくなるため、インデックスも迅速に行われることが多いです。たとえば、更新頻度が高いニュースサイトやブログはクローラーが頻繁に巡回するため、最新の情報が検索結果に表示されやすくなります。逆に、クローラーがほとんど訪れないサイトはインデックスに時間がかかったり、検索結果に表示されなかったりする可能性が高まります。
クローラーが回りやすいサイト
クローラーがサイトを隅々まで効率よく巡回できると、検索エンジンはサイト内のすべてのページを理解しやすくなります。これにより、サイト全体の評価が高まるだけでなく、各ページが適切なキーワードでインデックスされるため、より多くの検索結果に表示されやすくなります。クローラーが回りやすいサイト作成の方法として、内部リンクやサイトマップがあります。
- 内部リンク:内部リンクを適切に設定することで、クローラーがページ同士の関連性を理解しやすくなり、全ページを巡回しやすくなります。
- サイトマップ:サイトマップを設置すると、クローラーがサイト内のすべてのページを簡単に見つけられるため、SEOにおいて有利に働きます。
クローラーの制御方法:見せたくないページをクロールさせないための設定方法
なぜクロールを制限する必要があるのか?
すべてのページを検索エンジンにクロールさせることが必ずしも良いわけではありません。クローラーには巡回の回数制限があるため、優先してインデックスされたいページが多い場合には、見せたくないページを制限することでクローラーの巡回を効率的に管理できます。以下のようなページはクロールの制限対象になることが多いです。
- プライベート情報が含まれるページ:たとえば、ユーザー専用のダッシュボードや会員ページなど、個別のログインが必要なページ。これらがインデックスされると、検索結果に個別のリンクが表示されてしまう恐れがあります。
- 重複コンテンツのページ:同じ内容が異なるURLで複数存在する場合、クローラーがそれぞれを別々のページと判断してしまい、SEO上の評価が分散されてしまう可能性があります。
- 特定のパラメータが含まれるURL:サイト内の検索結果ページや特定のフィルタがかかったURLなども、SEO上あまり有利にならないため、クロールを避けることが一般的です。
クロール制限をかける基本方法:robots.txtファイル
Webサイトのサーバーに配置するテキストファイルで、検索エンジンのクローラー(ボット)に対してサイト内のどのページをクロール(巡回)しても良いか、またはクロールしないでほしいかを指示するためのものです。このファイルを使用することで、サイトのSEOを管理し、検索エンジンに不要なページをインデックスさせないように制御することができます。
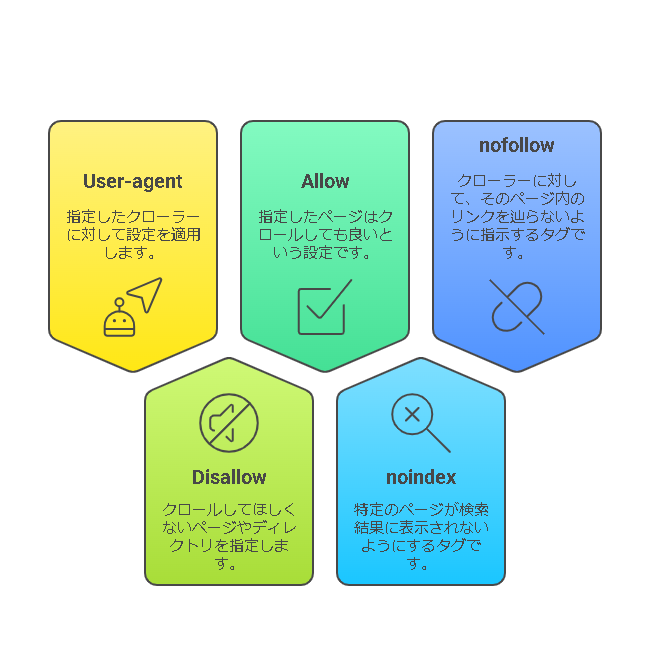
- User-agent:指定したクローラーに対して設定を適用します。たとえば、「*」はすべてのクローラーを意味します。
- Disallow:クロールしてほしくないページやディレクトリを指定します。
- Allow:指定したページはクロールしても良いという設定です。
- noindex:特定のページが検索結果に表。示されないようにするタグです。例えば、インデックスさせたくない確認ページや特定の情報ページに「noindex」を設定することで、検索結果にそのページが現れないようにします。
- nofollow:クローラーに対して、そのページ内のリンクを辿らないように指示するタグです。外部リンクを辿らせたくない場合や、SEO評価を分散させたくない場合に利用されます。
〈一例〉
User-agent: *
Disallow: /private/
Disallow: /search-results/
Allow: /public/
この例では、すべてのクローラー(User-agent: *)に対して、/private/と/search-results/のページはクロールしないように指示しています(Disallow)。ただし、/public/ディレクトリ内のページはクロールしても良いという設定です(Allow)。
これらの設定により、クローラーに巡回してほしいページと巡回してほしくないページを効率よく管理できるようになります。
クローラーの注意点 よくあるクロールエラーとその対策
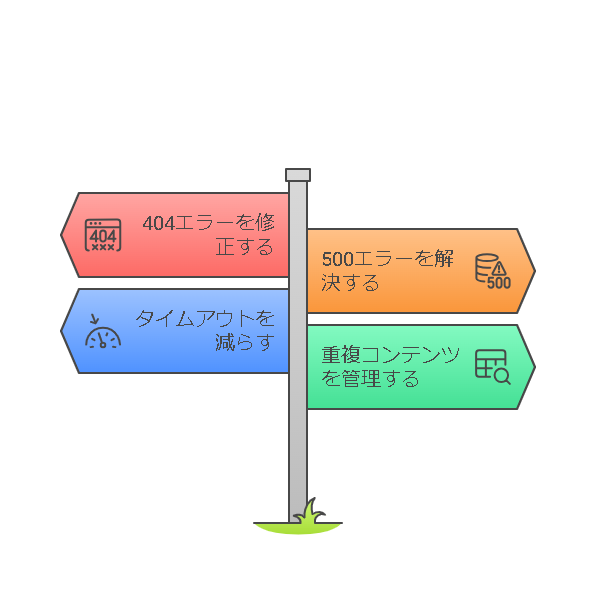
404エラー(ページが見つからない)
404エラーは、クローラーが存在しないページにアクセスしようとした際に発生します。例えば、過去のブログ記事や商品のリンクが削除された際に、他のページや外部サイトからそのリンクが残っている場合、クローラーがアクセスできず404エラーが発生します。
〈対策〉Googleサーチコンソールなどのツールで404エラーが出ているページを確認し、適切な対応を行いましょう。リンク先が削除された場合には、該当ページを新しいURLにリダイレクトさせるか、関連するページへのリンクに修正するのが有効です。
500エラー(サーバーエラー)
500エラーは、サーバーに問題があるときに発生するエラーで、サイトが一時的にダウンしているときやサーバーの設定に問題がある場合に発生します。例えば、サイトにアクセスが集中してサーバーが応答できない時や、内部エラーが原因でページが表示されない時に500エラーが発生します。
〈対策〉500エラーは、サーバーの状態や設定の確認が必要です。サーバーのホスティング会社に問い合わせる、またはサーバー設定を見直すことで、問題を解決することができます。必要に応じてキャッシュ機能を利用して負荷を分散させましょう。
タイムアウトエラー(応答が遅い)
タイムアウトエラーは、ページの読み込みが遅すぎてクローラーがアクセスをあきらめる場合に発生します。例えば、画像やスクリプトが多すぎてページの読み込みが遅延したり、サーバーが応答に時間がかかりすぎるとタイムアウトエラーが発生します。このエラーが発生すると、クローラーが巡回できず、インデックスも行われません。
〈対策〉ページの読み込み速度を改善することが重要です。画像の最適化やJavaScriptの読み込み順の見直し、必要のないプラグインの削除、キャッシュの活用などを行い、ページの表示速度を向上させましょう。Googleの「PageSpeed Insights」などのツールでページ速度を確認し、改善点をチェックするのも効果的です。
重複コンテンツによるエラー
重複コンテンツは、同じ内容のページが異なるURLで存在する場合に発生します。たとえば、「/product」と「/product?ref=homepage」など、同じ商品ページが複数のURLでアクセスできる場合、クローラーはどのURLをインデックスすべきか迷ってしまいます。その結果、評価が分散してSEO効果が薄くなることがあります。
〈対策〉重複コンテンツを防ぐためには、「canonicalタグ」を使って正規のURLを指定する方法が有効です。これにより、クローラーに対してどのページが「本物のページ」であるかを明示的に伝え、評価を一箇所に集中させることができます。
これらのエラーはGoogleサーチコンソールなどのツールで確認し、ページを修正して早期に解決することが重要です。エラーが長期間放置されると、検索エンジンに悪影響を与える可能性があります。
まとめ
Webサイトのクローラー制御は、SEOを効果的に管理するために欠かせない重要な手段です。特に「robots.txtファイル」を使って、クローラーに巡回させたくないページを指示することで、検索エンジンに不必要な情報がインデックスされるのを防ぐことができます。また、「noindex」や「nofollow」のタグを使うことで、個別のページやリンクに対してより細かい制御が可能です。これらの設定を適切に活用することで、サイトの評価を向上させ、検索エンジンにとって重要なページだけがしっかりとインデックスされるようになります。まずは自サイトでクロールさせたいページとさせたくないページの分類から始めてみましょう!
この記事を読んだ方におすすめの記事はこちら!
- プロフィール
-
- 経済学部出身。 SEO・SNS・オウンドメディア運用を軸に250本超の記事を執筆。 企画・ディレクションも担当し、検索意図に応える構成と実践的なSEOノウハウを提供。









